
O relatório de Estatísticas de Rastreamento do Google Search Console possibilita acompanhar, de forma detalhada, a atuação do Googlebot em um site. Por meio desse recurso, é possível compreender como, quando e com que frequência o Google acessa as URLs, além de identificar padrões de rastreamento que impactam diretamente o desempenho em SEO.
Embora seja uma funcionalidade pouco explorada, o relatório está disponível dentro do Search Console e oferece informações valiosas para análises avançadas de SEO técnico. A partir desses dados, profissionais podem trabalhar a otimização do crawl budget, detectar quedas anormais no rastreamento, identificar lentidão ou falhas no servidor e antecipar problemas que afetam a indexação das páginas.
Neste novo capítulo do guia da SHH sobre Google Search Console, você aprenderá de forma prática e aprofundada como utilizar o relatório de Estatísticas de Rastreamento. O conteúdo aborda como interpretar os dados, em quais cenários o relatório é mais útil e quais indicadores merecem atenção para melhorar a visibilidade orgânica nos resultados de busca.
Como funcionam as Estatísticas de Rastreamento no Google Search Console?
Antes de analisar o relatório, é fundamental compreender o funcionamento do processo de rastreamento do Google. Sem essa etapa, nenhuma página pode ser exibida nos resultados de pesquisa.
De maneira simplificada, o rastreamento consiste no processo em que o Google acessa e baixa os elementos de uma URL, como arquivos HTML, CSS, JavaScript e imagens. Quando o conteúdo atende aos critérios de relevância e qualidade, ele é incluído no índice do Google — processo conhecido como indexação.
Esse trabalho é executado pelo Googlebot, o robô responsável por descobrir novas URLs, enviar requisições ao servidor, analisar o conteúdo das páginas, seguir links internos e externos, além de interpretar redirecionamentos. O comportamento desse robô influencia diretamente a eficiência de indexação e o desempenho do site em SEO.
Existem diferentes métodos para controlar quais áreas de um site podem ou não ser acessadas pelos rastreadores de mecanismos de busca. Entre os principais recursos está o arquivo robots.txt, responsável por informar, em linguagem legível para robôs, quais URLs estão autorizadas ou bloqueadas para rastreamento.
Em sites de pequeno porte, o Googlebot geralmente consegue percorrer todas as páginas disponíveis sem restrições relevantes. No entanto, em sites grandes, com centenas de milhares ou até milhões de URLs, o rastreamento ocorre de forma limitada. Nesses casos, entra em cena o crawl budget, também conhecido como orçamento de rastreamento, que define a quantidade máxima de páginas que o Google consegue rastrear em determinado período.
O relatório de Estatísticas de Rastreamento do Google Search Console reúne informações detalhadas sobre esse processo. A ferramenta mostra quais URLs o Googlebot tentou acessar, com que frequência isso ocorreu, quais tipos de recursos foram baixados (como HTML, CSS, JavaScript e imagens), além de outros dados técnicos essenciais para SEO técnico e indexação.
Na prática, esse relatório funciona como uma central de monitoramento do rastreamento, permitindo analisar como o Googlebot interagiu com o site ao longo dos últimos meses e identificar gargalos que podem comprometer a performance orgânica.
Quando utilizar o relatório de Estatísticas de Rastreamento?
O relatório de Estatísticas de Rastreamento não costuma fazer parte da análise diária da maioria dos sites. Apesar de sua relevância, ele possui um escopo mais técnico e específico quando comparado a outros relatórios do Google Search Console, como o relatório de desempenho nos resultados de pesquisa.
Seu uso é especialmente estratégico em sites de grande porte, nos quais a gestão do rastreamento é uma etapa fundamental do SEO. Em ambientes com milhões de páginas, é essencial direcionar o crawl budget para URLs prioritárias, garantindo que conteúdos relevantes sejam rastreados e indexados com maior eficiência.
Já em sites menores, o relatório costuma ser utilizado de forma pontual, principalmente para diagnosticar problemas técnicos, como aumento repentino de erros 5xx, instabilidades no servidor ou falhas que impactam o acesso do Googlebot.
Como analisar o relatório de Estatísticas de Rastreamento
Para acessar o relatório, basta entrar no menu Configurações do Google Search Console. Dentro da seção de rastreamento, estará disponível a opção Estatísticas de Rastreamento.
Ao abrir o relatório, o usuário encontra um gráfico de barras acompanhado por listas detalhadas, que apresentam os dados de rastreamento do site referentes aos últimos 90 dias. Essas informações permitem identificar tendências, variações anormais e oportunidades de otimização relacionadas ao rastreamento, crawl budget e SEO técnico.
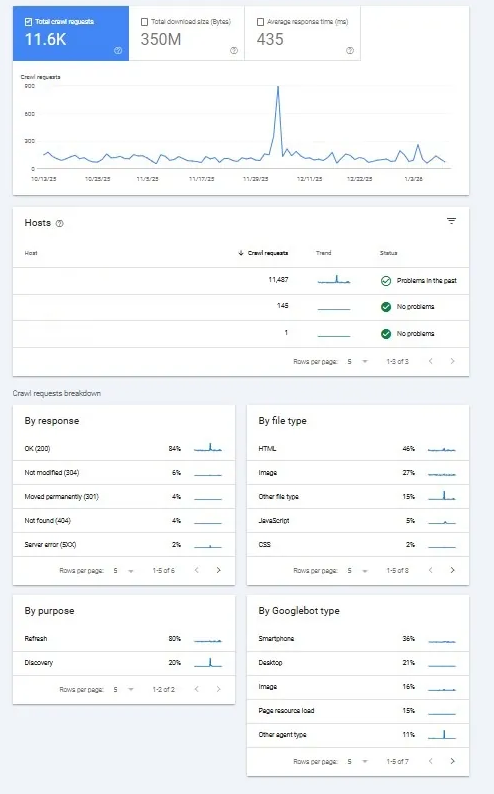
O relatório de Estatísticas de Rastreamento do Google Search Console é composto por diversos indicadores técnicos que permitem compreender, com precisão, como o Googlebot interage com um site. Cada elemento do relatório fornece dados essenciais para análises avançadas de rastreamento, crawl budget e performance técnica em SEO.
Principais métricas do relatório de Estatísticas de Rastreamento
- Total de requisições: indica o número de vezes que o Googlebot realizou acessos ao site durante o período analisado, refletindo a intensidade do rastreamento.
- Volume de recursos processados: representa a quantidade de dados que o Googlebot leu, interpretou e baixou, incluindo arquivos como HTML, CSS, JavaScript e imagens.
- Tempo de resposta do servidor: mede o intervalo necessário para o servidor responder a cada requisição HTTP feita pelo Googlebot, sendo um indicador direto de desempenho e estabilidade do servidor.
- Domínios e subdomínios: apresenta informações segmentadas por domínio e subdomínio, como
www.exemplo.com.broublog.exemplo.com.br, permitindo identificar diferenças no comportamento de rastreamento. - Códigos de resposta HTTP: mostra a proporção de requisições bem-sucedidas e com falhas, detalhando os status HTTP e suas causas, fundamentais para identificar erros que afetam a indexação.
- Finalidade do rastreamento: indica se o Googlebot estava descobrindo novas páginas ou revisitando URLs já conhecidas, ajudando a entender o ciclo de atualização do índice.
- Tipo de Googlebot: identifica qual versão do robô acessou o site, como Googlebot para dispositivos móveis, desktop, imagens ou outros agentes específicos.
As análises técnicas do relatório são realizadas a partir do cruzamento dessas métricas, permitindo identificar gargalos, priorizar correções e direcionar melhor o crawl budget para URLs estratégicas.
Informações relevantes sobre o uso do relatório
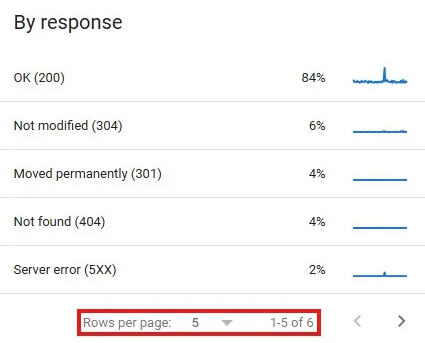
- O gráfico de barras não permite aplicação de filtros, diferentemente de outros relatórios do Google Search Console. Também não é possível definir intervalos personalizados ou comparar períodos, estando limitado à visualização dos últimos 90 dias.
- O gráfico apresenta exclusivamente o total de requisições, o volume de recursos processados e o tempo de resposta do servidor, sem detalhamento adicional por tipo de URL ou status.
- Cada seção do relatório é exibida de forma paginada, um detalhe simples, mas relevante, que pode passar despercebido durante análises mais rápidas.
A seguir, confira a explicação de cada métrica do relatório e entenda como esses indicadores influenciam diretamente o SEO técnico do site e a eficiência do rastreamento pelo Google.
Quantidade total de requisições
A quantidade total de requisições representa o número de vezes que o Googlebot tentou acessar o site durante o período analisado no Google Search Console. Esse volume inclui tanto as URLs das páginas quanto os recursos necessários para o carregamento do conteúdo, como imagens, arquivos CSS e JavaScript hospedados no próprio domínio.
Essa métrica é fundamental para avaliar a intensidade do rastreamento, identificar variações anormais no comportamento do Googlebot e entender como o crawl budget está sendo distribuído entre páginas e recursos. Um aumento ou queda abrupta no total de requisições pode indicar problemas técnicos, alterações estruturais no site ou limitações no desempenho do servidor, impactando diretamente a indexação e a visibilidade orgânica.
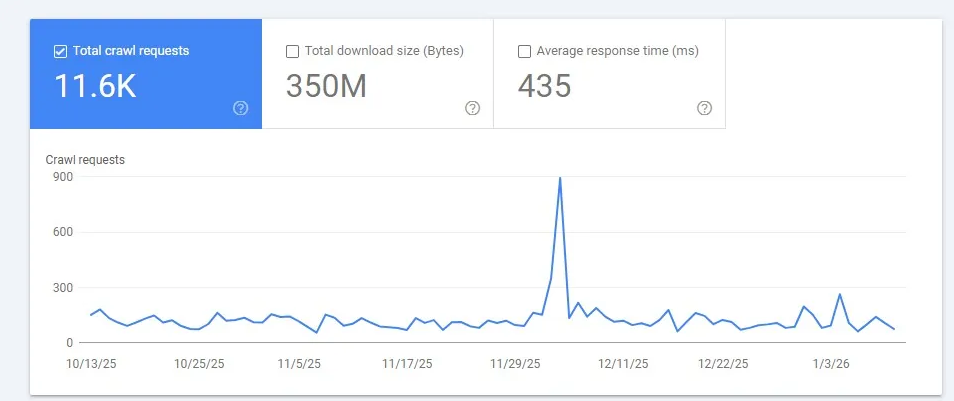
As tentativas de rastreamento sem sucesso também são consideradas no cálculo da quantidade total de requisições. Isso ocorre, principalmente, nas seguintes situações:
- Requisições interrompidas devido à indisponibilidade do arquivo robots.txt, impedindo o Googlebot de validar permissões de acesso.
- Falhas relacionadas ao DNS ou à disponibilidade do servidor, que impossibilitam a resposta adequada às solicitações do Googlebot.
- Requisições abandonadas em razão de cadeias extensas de redirecionamentos, que dificultam ou impedem o acesso ao conteúdo final.
Diversos fatores podem provocar variações no volume de requisições, tanto para cima quanto para baixo. Entre os mais comuns estão alterações no código-fonte do site, mudanças na arquitetura da informação e o aumento no número de URLs dentro do domínio.
Em sites de grande porte, é especialmente importante monitorar questões técnicas como navegação facetada, conteúdo duplicado e soft 404. Esses problemas tendem a gerar rastreamentos desnecessários, consumindo o crawl budget sem contribuir para a indexação de páginas relevantes, o que impacta negativamente o desempenho em SEO.
Tamanho dos recursos processados
O tamanho dos recursos processados corresponde ao volume total de bytes baixados pelo Googlebot durante o rastreamento do site. Esse indicador reflete o peso dos arquivos acessados, incluindo páginas e recursos estáticos.
Quando um mesmo recurso é utilizado por diversas páginas, o Googlebot faz o download apenas na primeira solicitação. A partir disso, o arquivo é armazenado em cache e não volta a ser contabilizado nas requisições subsequentes, o que otimiza o processo de rastreamento e reduz o consumo de recursos do servidor.
Essa métrica é relevante para identificar excessos no tamanho dos arquivos, gargalos de performance e oportunidades de otimização de recursos, contribuindo para um rastreamento mais eficiente e melhor SEO técnico.
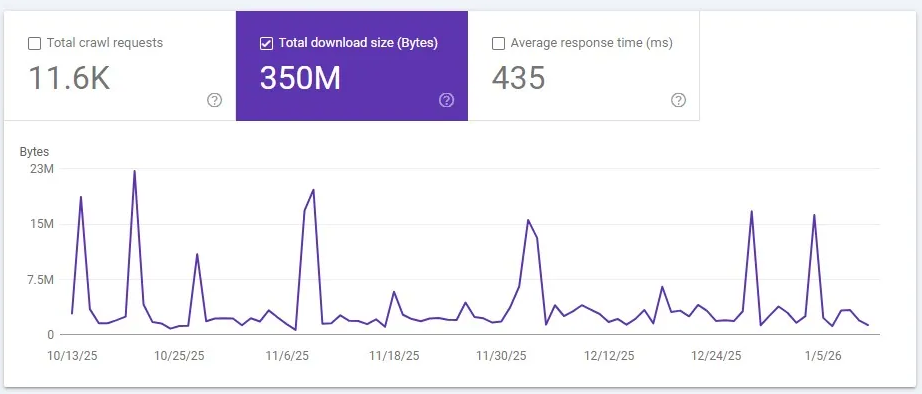
Picos no gráfico de recursos processados podem sinalizar a existência de páginas excessivamente pesadas, o que tende a reduzir a eficiência do rastreamento realizado pelo Googlebot. Para confirmar esse cenário, é recomendável cruzar essa informação com o total de requisições e com o tempo médio de resposta do servidor, avaliando se há correlação entre volume de dados, frequência de acessos e lentidão nas respostas.
Em sites de pequeno e médio porte, esse tipo de comportamento geralmente não representa um problema recorrente, pois o volume de URLs e recursos costuma ser mais controlado. Ainda assim, a análise preventiva contribui para a manutenção da saúde técnica do site e evita gargalos futuros.
Tempo médio de resposta do servidor
O tempo médio de resposta do servidor corresponde ao intervalo necessário para que o servidor envie o primeiro byte de dados ao Googlebot após o recebimento de uma requisição de rastreamento. Esse indicador, conhecido como Time to First Byte (TTFB), é um fator relevante para o SEO técnico e para a eficiência do rastreamento.
Cada recurso carregado por uma página — como arquivos HTML, CSS e JavaScript — é contabilizado individualmente nessa métrica. O valor é apresentado em milissegundos (ms) e permite identificar problemas de desempenho, lentidão no servidor ou gargalos de infraestrutura, que podem impactar tanto o rastreamento quanto a indexação das páginas no Google.
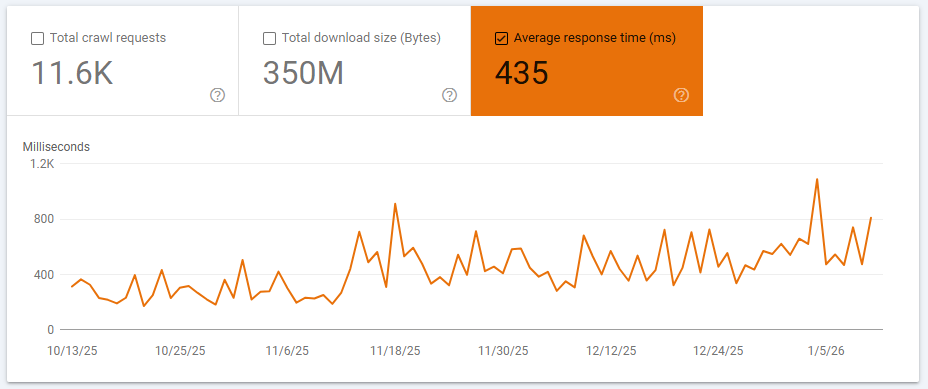
O tempo médio de resposta do servidor deve ser mantido o mais baixo possível para garantir um rastreamento eficiente pelo Googlebot e preservar a performance em SEO técnico. Como referência:
- O ideal é que o tempo de resposta permaneça próximo de 100 milissegundos (ms);
- Valores que se aproximam ou ultrapassam 1.000 ms tendem a gerar impactos negativos no SEO, especialmente em sites com grande volume de páginas.
Quando o servidor apresenta respostas lentas, o Googlebot passa a rastrear o site de forma menos eficiente. Nesse cenário, o robô gasta mais tempo em cada URL, pode reduzir a frequência de requisições e, em situações mais críticas, deixa de processar recursos relevantes das páginas, comprometendo a indexação completa do conteúdo.
Essas limitações afetam diretamente a visibilidade orgânica nos mecanismos de busca e também podem prejudicar a exposição do site em experiências baseadas em inteligência artificial do Google, que dependem de conteúdo bem rastreado e indexado.
Domínios e subdomínios
A seção de domínios e subdomínios (hosts) do relatório de Estatísticas de Rastreamento apresenta informações estratégicas sobre o comportamento do Googlebot, com foco em dois pontos principais:
- Quais domínios e subdomínios foram efetivamente rastreados, como versões com ou sem
www, áreas específicas do site ou subdomínios dedicados; - Ocorrência de problemas de disponibilidade em cada domínio ou subdomínio, permitindo identificar falhas de acesso, instabilidades no servidor ou configurações inadequadas que impactam o rastreamento.
Esses dados são fundamentais para diagnosticar problemas técnicos, otimizar a arquitetura do site e garantir que todas as áreas relevantes estejam acessíveis ao Googlebot, fortalecendo o SEO técnico e a indexação.
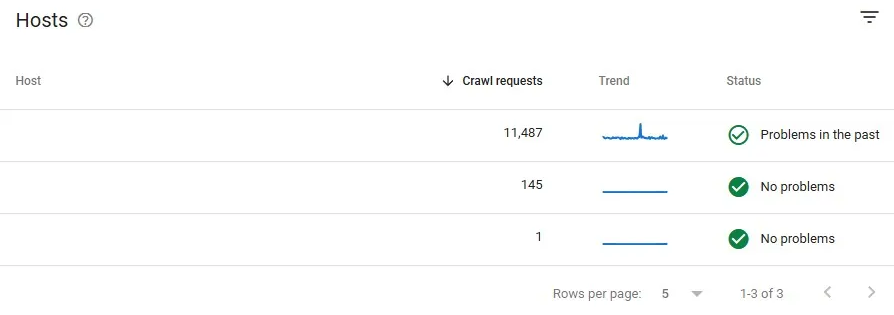
Domínios e subdomínios no relatório de Estatísticas de Rastreamento
Domínios e subdomínios representam os diferentes endereços utilizados para estruturar um site:
- O domínio principal corresponde ao endereço base, como
seusite.com.br; - O subdomínio funciona como uma extensão do domínio, a exemplo de
blog.seusite.com.br, geralmente utilizado para separar áreas específicas do site.
O relatório de Estatísticas de Rastreamento do Google Search Console disponibiliza informações detalhadas de até 20 domínios e subdomínios. Cada host pode ser analisado individualmente, bastando selecionar o respectivo nome para visualizar os dados específicos de rastreamento.
É importante destacar que subdiretórios não são exibidos separadamente nesse relatório. Dessa forma, seções como seusite.com.br/blog não podem ser filtradas de forma isolada. Nesses casos, os dados de rastreamento aparecem consolidados no domínio principal, o que exige atenção extra na interpretação das métricas.
Status de disponibilidade dos domínios
Para cada domínio ou subdomínio analisado, o relatório apresenta um status de disponibilidade, que indica a qualidade do acesso do Googlebot nos últimos 90 dias. Os status possíveis são:
- Sem problemas: não foram identificadas dificuldades de rastreamento no período analisado;
- Problemas no passado: ocorreu um problema relevante nos últimos 90 dias, porém não houve novos registros na última semana;
- Problema recente: o Google detectou uma falha significativa de acesso nos últimos sete dias.
Sempre que o status não estiver classificado como sem problemas, é recomendável realizar uma análise técnica. A ocorrência pode estar relacionada a eventos temporários, como manutenções programadas, ou a falhas persistentes que exigem correção imediata para evitar impactos no SEO.
Principais problemas de disponibilidade monitorados
Os fatores que influenciam o status de disponibilidade incluem, principalmente:
- Falhas na leitura do arquivo robots.txt, seja por retorno de erro 404 ou por configuração incorreta;
- Problemas de DNS, como ausência de resposta durante as tentativas de rastreamento;
- Indisponibilidade ou respostas incompletas do servidor, impedindo o acesso adequado do Googlebot.
Quando qualquer um desses problemas ocorre, o Googlebot interrompe o rastreamento temporariamente e tenta acessar o site novamente em outro momento, o que pode comprometer a indexação e a atualização das páginas.
Códigos de resposta HTTP
Sempre que o Googlebot solicita o acesso a uma página, o servidor retorna um código de resposta HTTP, composto por três dígitos, que indica se a requisição foi processada com sucesso ou se ocorreu algum erro.
No relatório de Estatísticas de Rastreamento, é possível visualizar quais códigos HTTP foram encontrados durante o rastreamento, permitindo identificar falhas de acesso, redirecionamentos incorretos ou erros que afetam diretamente o SEO técnico e a visibilidade do site nos mecanismos de busca.
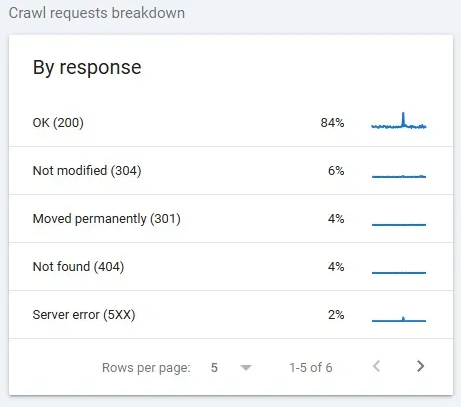
O Google classifica os códigos de resposta HTTP em três categorias principais: respostas adequadas, respostas que exigem atenção e respostas problemáticas. Essa classificação auxilia na avaliação da qualidade do rastreamento e no diagnóstico de falhas que podem comprometer o SEO técnico e a indexação das páginas.
Códigos de resposta HTTP adequados
Os códigos considerados adequados não demandam ações corretivas, pois indicam que a requisição foi processada corretamente e que o Googlebot conseguiu acessar e rastrear o conteúdo. Entre eles estão:
- 200 (OK): confirma que a solicitação foi bem-sucedida e que a página está acessível para rastreamento e indexação;
- 301 (Moved Permanently): indica um redirecionamento permanente. O Googlebot passa a considerar apenas a URL de destino como válida;
- 302 (Moved Temporarily): representa um redirecionamento temporário. O Googlebot segue a URL de destino, mas entende que a mudança não é definitiva;
- 304 (Not Modified): informa que o conteúdo não sofreu alterações desde o último rastreamento, permitindo economia de recursos durante o processo.
Códigos de resposta potencialmente adequados
Os códigos potencialmente adequados não caracterizam, por si só, um erro técnico, mas exigem verificação cuidadosa, pois podem indicar um comportamento inesperado que afeta a experiência do usuário ou o SEO.
O principal exemplo é o 404 (Not Found). Quando a URL realmente não existe mais e não há conteúdo equivalente, nenhuma ação é necessária. No entanto, se o status 404 ocorre em uma página válida — como em casos de links quebrados ou falhas de configuração —, a correção é essencial para evitar prejuízos à indexação e à autoridade do site.
Códigos de resposta HTTP problemáticos
Os códigos considerados problemáticos indicam falhas que precisam ser corrigidas, pois geralmente impedem o rastreamento adequado e reduzem as chances de a URL aparecer nos resultados de busca do Google. Os principais são:
- 401 / 407 (Não autorizado): indicam que o acesso à página foi bloqueado para o Googlebot. É necessário revisar as permissões, desbloquear a URL ou ajustar as regras no arquivo robots.txt;
- 5xx (Erro de servidor): ocorrem quando o servidor está indisponível ou não consegue processar a requisição. Falhas pontuais costumam ser toleradas, mas erros recorrentes exigem correção imediata;
- 4xx (Erros do cliente): abrangem diferentes situações em que a requisição não pode ser concluída, como páginas proibidas, recursos bloqueados ou excesso de solicitações ao servidor.
A presença contínua desses códigos afeta negativamente o rastreamento, a indexação e o desempenho em SEO técnico.
Tipos de arquivos rastreados
A seção de tipos de arquivos rastreados indica, em formato percentual, quais formatos de recursos o Googlebot acessou durante o rastreamento, como HTML, imagens, scripts e outros arquivos. Esses dados ajudam a entender como o orçamento de rastreamento está sendo utilizado e a identificar oportunidades de otimização de recursos para melhorar a eficiência do SEO técnico.
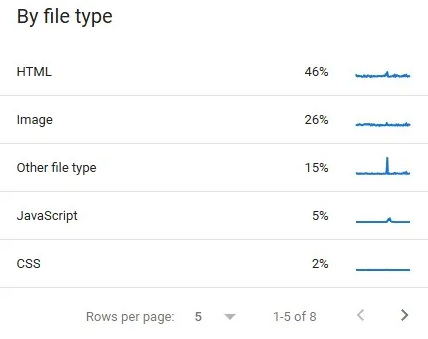
Tipos de elementos rastreados pelo Googlebot
O relatório de Estatísticas de Rastreamento do Google Search Console apresenta a distribuição dos tipos de arquivos acessados pelo Googlebot durante o rastreamento do site. Entre os formatos monitorados, estão:
- HTML;
- Imagens;
- Vídeos;
- Arquivos JavaScript;
- Arquivos CSS;
- Documentos PDF;
- Arquivos XML;
- Arquivos JSON;
- Feeds RSS e Atom;
- Arquivos de áudio;
- Dados geográficos, como arquivos KML.
Além desses formatos, o relatório também exibe a categoria “outros”, que engloba tipos adicionais de requisições, incluindo redirecionamentos. Já a classificação “desconhecido” corresponde a requisições mal-sucedidas, nas quais o Googlebot não conseguiu identificar ou acessar corretamente o recurso solicitado.
Essas informações são especialmente úteis para diagnósticos técnicos pontuais. Por exemplo, ao identificar um tempo de resposta do servidor elevado, é recomendável verificar quais tipos de arquivos estão sendo rastreados com maior frequência. Em muitos casos, o Googlebot pode estar consumindo recursos excessivos ao acessar imagens desnecessárias, arquivos pesados ou ao seguir cadeias de redirecionamentos extensas, impactando negativamente o crawl budget e o SEO técnico.
Propósito do rastreamento
A seção propósito do rastreamento indica o motivo pelo qual o Googlebot acessou cada URL do site. O relatório classifica essas ações em duas categorias principais:
- Descoberta: corresponde ao primeiro rastreamento de uma página, quando o Google identifica uma nova URL;
- Atualização: refere-se ao rerastreamento de páginas já conhecidas, realizado para verificar alterações no conteúdo ou nos recursos.
A análise desse indicador ajuda a compreender como o Google prioriza o rastreamento, identificar oportunidades de otimização e garantir que páginas estratégicas sejam rastreadas e atualizadas com maior frequência, fortalecendo a indexação e a performance orgânica.
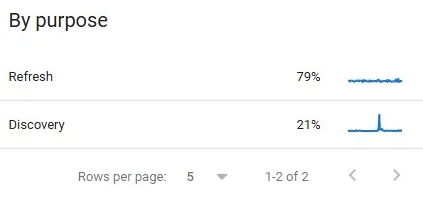
Esse indicador é relevante para análises específicas, especialmente quando há a necessidade de investigar anomalias no comportamento de rastreamento. Entre os principais cenários em que essa métrica se torna útil, destacam-se:
- Aumento expressivo no volume de descobertas, o que pode indicar que o Googlebot está rastreando URLs de baixo valor para SEO, como páginas duplicadas, filtros ou parâmetros desnecessários;
- Redução no número de atualizações, sinalizando que o Google pode estar diminuindo a frequência de rastreamento do site, o que impacta a atualização do índice;
- Demora no rerastreamento de páginas atualizadas, situação que exige a verificação da presença dessas URLs no sitemap XML, garantindo que o Google identifique rapidamente as mudanças realizadas.
A análise adequada desses padrões contribui para otimizar o crawl budget, priorizar páginas estratégicas e melhorar a eficiência da indexação.
Tipo de Googlebot
O Google utiliza diferentes tipos de Googlebot, cada um projetado para atender a finalidades específicas, como rastreamento para dispositivos móveis, desktop, conteúdos em vídeo, anúncios e outros contextos.
Na seção Tipo de Googlebot do relatório de Estatísticas de Rastreamento, é possível identificar quais versões do robô acessaram o site nos últimos 90 dias. Essa informação é fundamental para validar se o Google está priorizando o Googlebot para smartphone, alinhado à política de indexação mobile-first, além de auxiliar na identificação de eventuais problemas de compatibilidade ou bloqueios específicos que possam afetar o SEO técnico e a visibilidade orgânica.
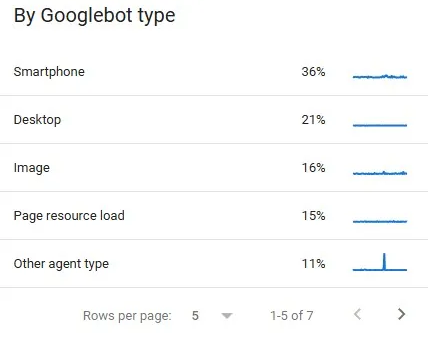
Embora seja uma informação relevante do ponto de vista técnico, esse indicador apresenta aplicabilidade prática limitada na maioria dos cenários. Em geral, o rastreamento ocorre predominantemente por meio do Googlebot para dispositivos móveis, seguido pelo Googlebot desktop, sem variações significativas que exijam análises aprofundadas.
Quais análises podem ser realizadas no relatório de Estatísticas de Rastreamento?
Os dados disponíveis no relatório de Estatísticas de Rastreamento do Google Search Console permitem acompanhar de forma precisa o crawl budget e a eficiência do rastreamento das páginas. À medida que o número de URLs de um site cresce, esse controle se torna cada vez mais relevante, pois, em ambientes de grande escala, pequenas otimizações técnicas podem gerar impactos significativos no desempenho orgânico.
Entre as principais análises que podem ser realizadas a partir do relatório, destacam-se:
- Avaliar se melhorias técnicas implementadas no site resultaram em aumento ou redução do volume de rastreamento;
- Identificar quais seções do site são rastreadas com maior frequência pelo Google;
- Confirmar se áreas que não devem ser rastreadas, como seções internas ou administrativas, estão corretamente bloqueadas;
- Verificar se recursos essenciais, como arquivos JavaScript e CSS, estão sendo rastreados adequadamente;
- Detectar períodos de indisponibilidade do servidor, mesmo que pontuais;
- Analisar se o crawl budget está sendo direcionado a recursos relevantes, evitando desperdício com URLs de baixo valor;
- Avaliar a qualidade e estabilidade do servidor, por meio da incidência de erros 5xx;
- Confirmar se a infraestrutura suporta o volume atual de requisições do Googlebot;
- Garantir que os user agents do Googlebot não estejam bloqueados de forma indevida, seja por configurações incorretas ou regras mal aplicadas.
Como é possível observar, trata-se de um conjunto de análises técnicas específicas, voltadas principalmente para diagnóstico e otimização avançada de SEO técnico. Portanto, na ausência de quedas de visibilidade, problemas de indexação ou falhas de rastreamento, não há necessidade de consultar esse relatório com alta frequência.
A periodicidade ideal de análise depende diretamente da complexidade e da estrutura do site. Em alguns projetos, uma verificação mensal é suficiente; em outros, especialmente em sites menores, o relatório pode ser consultado de forma ainda mais esporádica, sem prejuízos ao desempenho orgânico.
Para lidar com desafios avançados de SEO técnico e estratégico, é essencial contar com um especialista experiente. Eu sou o responsável pela Celos SEO e atuo diretamente na otimização de sites de médio e grande porte, incluindo projetos com alcance nacional e internacional, aplicando estratégias alinhadas às melhores práticas do Google.
FAQ – Relatório de Rastreamento do Google Search Console e SEO
É um relatório que mostra como o Googlebot interage com seu site, incluindo número de acessos, tipos de recursos baixados e comportamento do rastreamento.
Ele ajuda a monitorar o uso do crawl budget, identificar erros de servidor e entender se as páginas estão sendo rastreadas eficientemente pelo Google.
No Google Search Console, vá em “Configurações” e clique na opção Estatísticas de Rastreamento.
É o limite de URLs que o Googlebot rastreia em um site em um período, influenciado pela capacidade do servidor e pela importância percebida das páginas.
Inclui total de requisições, tamanho de recursos processados e tempo de resposta do servidor.
Tempos longos podem reduzir a eficiência do rastreamento e limitar o número de páginas que o Googlebot consegue acessar.
Indica se o Googlebot estava descobrindo uma nova URL ou atualizando conteúdos já conhecidos.
Observe picos anormais de requisições, aumento de erros ou respostas HTTP problemáticas.
Sim, mas ele é mais útil em sites maiores, onde a gestão do crawl budget impacta diretamente o SEO.
Eles mostram se o Googlebot conseguiu acessar páginas com sucesso (200), se houve redirecionamentos ou falhas no servidor.
É o estado de disponibilidade do servidor ou domínio, indicando se o Googlebot teve dificuldades de acesso.
Ele mostra se o Google está gastando recursos em páginas importantes ou desperdiçando tempo em URLs de baixo valor.
Sim, ele exibe os formatos — como HTML, CSS, JS e imagens — para ajudar a identificar padrões de rastreamento.
Depende da complexidade do site; em grandes portais pode ser útil monitorar mensalmente ou após mudanças estruturais.
Não completamente — ele oferece uma visão amostrada do comportamento do Googlebot, mas não detalha todos os acessos como um log de servidor faria.



